¿Qué es?
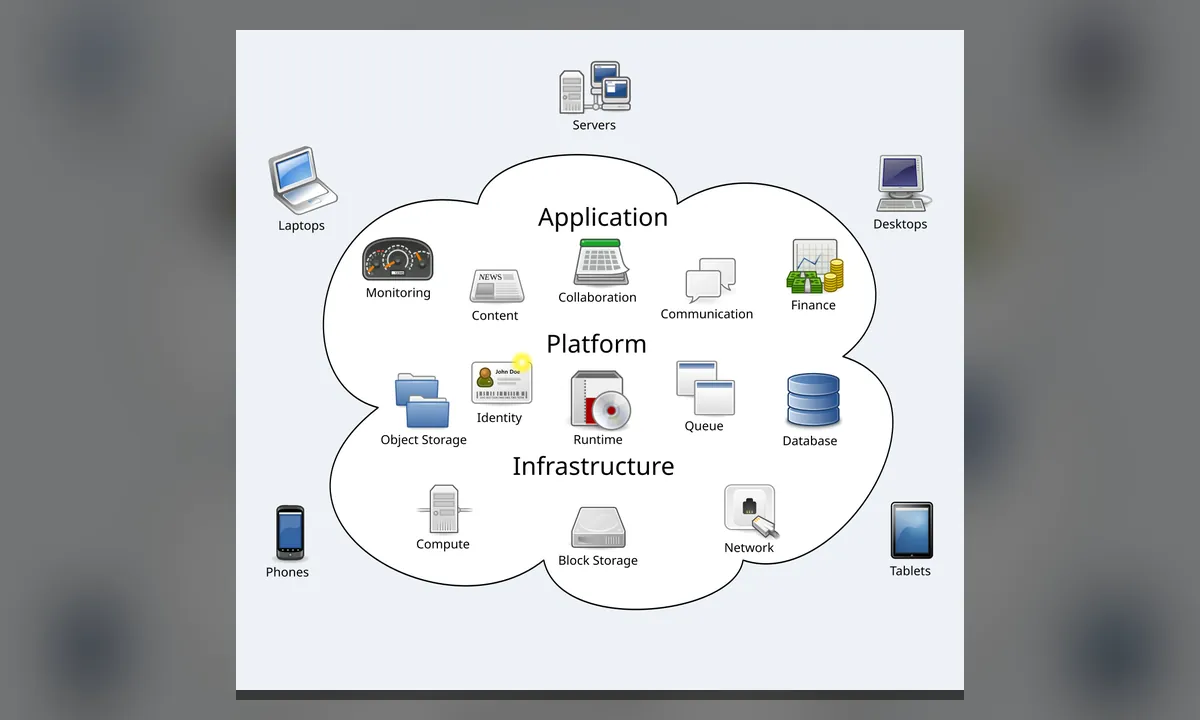
La computación en la nube permite utilizar recursos informáticos alojados en centros de datos remotos. En lugar de comprar y mantener todo el hardware, una organización puede solicitar capacidad, almacenamiento o aplicaciones y ajustarlos según necesidad.
Modelos principales
IaaS ofrece infraestructura virtual, PaaS proporciona plataformas para desarrollar y ejecutar software y SaaS entrega aplicaciones completas mediante navegador o cliente. También existen nubes públicas, privadas e híbridas según quién controla y comparte los recursos.
¿Qué ventajas ofrece?
Facilita desplegar servicios rápidamente, distribuirlos por regiones, escalar demanda y convertir parte de la inversión inicial en gasto por uso. Los proveedores pueden automatizar mantenimiento, redundancia y herramientas avanzadas que serían difíciles de construir de forma individual.
Riesgos y límites
La nube sigue funcionando en ordenadores físicos y depende de redes, configuración y proveedores. Errores de permisos, costes inesperados, caídas y dependencia tecnológica son riesgos reales. La responsabilidad de seguridad se reparte entre proveedor y cliente.
Idea clave
La nube no elimina la infraestructura: la concentra, automatiza y ofrece como servicio con responsabilidades compartidas.
Cómo profundizar en la computación en la nube
Delimita qué significa la computación en la nube, qué explica y qué casos quedan fuera.
En la computación en la nube, conecta «Modelos principales» con sus causas, condiciones y resultados observables.
Compara la computación en la nube con La computación cuántica para reconocer similitudes y límites.
Relacionar la computación en la nube con Las bases de datos: ordenar información para encontrarla sin caos aporta una pieza concreta: Una base de datos almacena información de forma estructurada para recuperarla y modificarla con fiabilidad. La conexión se vuelve clara al cambiar de escala o seguir el mecanismo hasta su siguiente consecuencia. Esta comparación convierte dos definiciones separadas en una explicación más amplia y ayuda a recordar por qué ambos temas aparecen próximos dentro de Simplao.
Relacionar la computación en la nube con El Internet aporta una pieza concreta: Internet es un conjunto descentralizado de redes de comunicaciones interconectadas que utilizan el protocolo TCP/IP. Compararlos permite distinguir lo que comparten de aquello que pertenece solo a uno de los dos fenómenos. Esta comparación convierte dos definiciones separadas en una explicación más amplia y ayuda a recordar por qué ambos temas aparecen próximos dentro de Simplao.
La evidencia sobre la computación en la nube se vuelve especialmente útil cuando permite comparar rendimiento, consumo, fiabilidad, accesibilidad y coste total, no una única cifra promocional. Un dato aislado puede ser correcto y aun así resultar engañoso si se desconoce cómo se obtuvo, qué margen de error tiene o con qué referencia se está contrastando. Leer este asunto con profundidad significa atender tanto al resultado llamativo como al procedimiento que lo sostiene.
Para analizar la computación en la nube, los investigadores utilizan arquitecturas y abstracciones que separan componentes para poder diseñar, medir y corregir sistemas complejos. Un modelo no pretende copiar cada detalle: selecciona las relaciones necesarias para responder una pregunta. Su valor se mide por la claridad de sus supuestos, la precisión de sus predicciones y su capacidad para fallar de una manera detectable cuando la idea es incorrecta.
En la computación en la nube, la escala cambia la interpretación porque una solución que funciona para cien usuarios puede comportarse de otro modo con millones, fallos parciales o atacantes. Antes de comparar dos cifras o ejemplos hay que comprobar si describen el mismo nivel, duración y contexto. Muchos aparentes desacuerdos desaparecen al descubrir que cada explicación estaba respondiendo a una pregunta distinta o trabajando en una escala diferente.
Al estudiar la computación en la nube también importa reconocer los límites: datos de entrenamiento, dependencias, errores humanos, vulnerabilidades y decisiones de diseño. Señalar una incertidumbre no debilita automáticamente el conocimiento; permite saber qué parte está bien establecida, cuál depende de supuestos y qué nueva observación podría mejorarla. La investigación avanza precisamente al convertir esas zonas inciertas en preguntas comprobables.
Una conexión útil aparece al comparar la computación en la nube con Las bases de datos: ordenar información para encontrarla sin caos, El Internet, Las API: contratos para que programas hablen entre sí. Los temas relacionados no son simples recomendaciones: permiten cambiar de escala, seguir una causa hasta sus consecuencias o observar el mismo principio desde otra disciplina. Construir esas conexiones produce una comprensión más estable que memorizar definiciones separadas.
La computación en la nube tiene valor más allá de su definición porque la tecnología reorganiza tareas y relaciones, por lo que sus efectos no son solo técnicos. Preguntarse quién mide, qué variable cambia y qué permanecería igual en otro escenario ayuda a pasar de una explicación introductoria a una comprensión capaz de aplicarse a casos nuevos.
Un error habitual al explicar la computación en la nube consiste en olvidar que nuevo no significa automáticamente mejor: una mejora debe medirse respecto a una necesidad y a sus costes. Las explicaciones sencillas son necesarias, pero deben conservar la frontera entre metáfora y evidencia. Cuando una frase parece absoluta, merece comprobar condiciones, excepciones y alcance antes de convertirla en una regla general.
El conocimiento sobre la computación en la nube no procede de un descubrimiento aislado. Se construye al acumular observaciones, corregir instrumentos, discutir interpretaciones y repetir análisis. Las conclusiones más fiables son las que sobreviven a preguntas nuevas y a equipos que intentan comprobarlas sin depender de la autoridad de quien las formuló primero.


